
I am currently looking for research fellows to participate in my summer 2023 undergraduate forestry data science research group (UFDS) at Harvard University. This opportunity is open to any Harvard students who are not graduating seniors. The ten week program will tentatively run from Monday June 5th to Friday August 11th at the Harvard Science Center. The application is due no later than Thursday January 26th. Selected students will then apply for SPUDS/PRISE funding. All selected students will be funded either through SPUDS/PRISE or one of my grants with the US Forest Service. The SPUDS/PRISE funding includes housing and a stipend (the amount of the 2023 stipend has not yet be released).
The summer 2023 UFDS application can be found here.
Students will work on problems generated by the US Forest Inventory and Analysis Program (FIA) and will collaborate directly with Research Statisticians and Foresters at FIA. FIA is responsible for monitoring the status and trends in forested ecosystems throughout the US. With the rise of new data sources, such as satellite imagery and large scale photography, and with the explosion of new statistical learning tools, a wealth of estimation techniques are available to consider. But with these new methods also come a load of important statistical questions related to robustness, bias, efficiency, and more!
Over the ten week period, students will work on approximately two projects in groups of 1-3. The overarching theme of the projects will be the development, evaluation, and distribution of statistical methods and tools for improving estimation of forest attributes. However, individual projects will vary from exploratory analyses to methodology comparisons to software and dashboard development. Here’s a rough timeline of the summer research process:
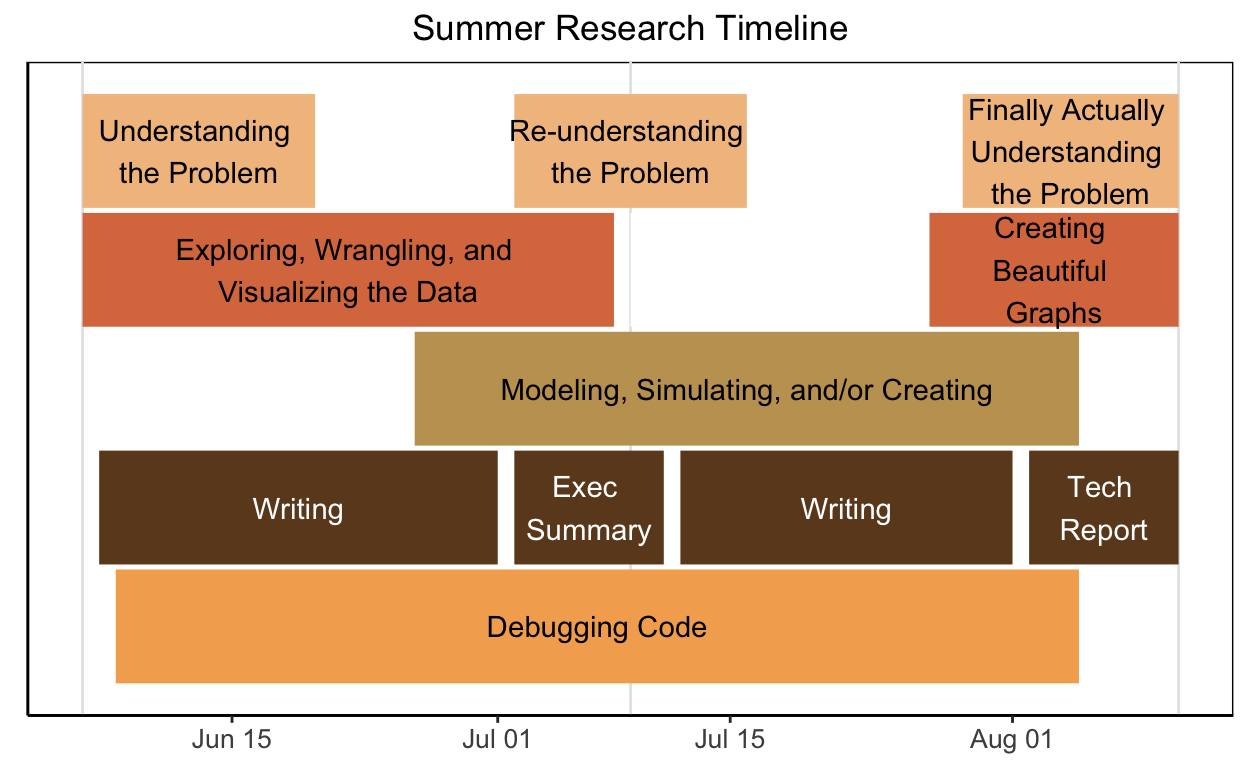
Here are some of the tentative projects for 2023:
Random Forests are a powerful predictive tool, but in the remote sensing and environmental literature they are getting a bad rap for being prone to overfitting. The problem is that people are unknowingly feeding their models cluster-correlated data (i.e., data collected in spatially or temporally correlated clusters) which leads to highly exaggerated accuracies, amongst other things. Through a series of simulations, we will clearly illustrate this problem and demonstrate potential solutions.
In recent years, FIA has experienced greater need for estimates of forest parameters over smaller geographic regions. For example, the Forest Service manages wild fires and tries to estimate the impact of these fires on important forest attributes. This area of research is called “small area estimation.” This project will explore the utility of a hybrid approach to small area estimation that makes use of estimators from two different classes: model-assisted estimators and model-based estimators.
FIA wants to understand changes in the land use over time and in particular if forest areas are increasing or decreasing. Currently FIA produces annual estimates using a simple weighted average and has difficulty obtaining precise enough estimates to discern change over short time scales. In this project, we will study the impacts on efficiency (i.e., the size of the standard error) when we (a) employ a more complicated estimators and (b) incorporate more remotely-sensed data. This project will also explore the land use data provided by Copernicus for estimating change.
A previous fellow and I wrote the R data package
pdxTreesusing data collected by the Portland Parks and Rec Department. I use this package extensively in my teaching and it is featured in Modern Data Science with R. Both Cambridge and Boston collect tree data and share the data through their open data portals. In this project, we will createRpackages and tutorial materials with these data.
FAQs
Q: Why should I spend my summer conducting research?
A: I have so many answers that I wrote a whole article about this question! Here’s the shortened version:
Learning by doing statistics: Practicing statistics can really help you develop as a statistician.
Communication skills: You will have multiple opportunities to share your work (both in writing and orally) to your peers, your mentor (me!), the stakeholders, and novices. I will give you feedback to help you hone your communication skills.
Professional identity and belonging: Research can help strengthen your connection to the discipline of statistics.
Graduate school and career preparation/clarity: The experience will demystify what research is, helping you decide if you want to pursue an advanced degree. And, grad school or not, the tools and skills learned will help prepare you for your professional life after undergrad.
And, it is fun: The data are messy! The questions are vague! The answers are unknown! What more could you want?
Q: Will I get to co-author a publication as part of this research opportunity?
A: At the start of a project, it is very difficult to predict whether or not it will result in a publication. And, for some projects, a journal article may not be the most useful final product. So, I can’t say with any certainty whether or not your work will be published but I can say that we will find ways for you to share the work. For example, the group will present their findings to FIA researchers and will be expected to participate in any relevant campus research presentation events. I will also strongly encourage you to submit the final technical report to the Undergraduate Statistics Research Project Competition and/or a video presentation to the Electronic Undergraduate Statistics Research Conference (eUSR). One of the 2022 projects won “Best Video Presentation” at this year’s eUSR! On top of all that, we will also look for relevant statistics and data science conferences for you to share the work.

Deliverables from previous projects have included journal articles, peer-reviewed technical reports, dashboards, and software development (links include an example of each).
Q: What will a typical day look like?
A: The work will be highly collaborative. Four days a week we will have a team meeting in the morning where everyone presents their progress, discusses issues, and talks through their next steps. For the rest of the day, your time will likely be split between your two projects and will be a mix of coding, writing, problem-solving, and dealing with merge conflicts in GitHub.
Q: What software will we use?
A: All our work will be done using R/RStudio and git/GitHub. Previous experience with R is required but previous experience with git is not.
What prior coursework is required?
A: The projects will vary in terms of the computational and statistical skills needed but each research fellow should have prior experience coding in R and building statistical models. I require students to have taken one of Stat 100, 102, 104, or 139 and Stat 108 (which is being offered in Spring 2023). Other useful but not required courses include Stat 111, Stat/CS 109a, Stat/CS 109b and an ecology course. If you haven’t taken the required courses, you are still encouraged to apply but should address your level of proficiency in R and your experience with statistical modeling in your application.
Do I need to be a statistics concentrator to apply?
A: No! While most my research students have tended to be statistics students, some of my fellows were concentrating in other disciplines such as Economics or English. Coming from a different field often brings a very valuable and unique perspective!